
ByteDance enthüllt Seed 1.5-VL: Ein wegweisendes Bild-Sprache-KI-Modell, das mit Gemini Pro 2.5 konkurriert
Als großer Fortschritt in der multimodalen Künstlichen Intelligenz hat das Seed Team von ByteDance sein neuestes großes Bild-Sprache-Modell, Seed 1.5-VL, veröffentlicht. Dies ist ein wichtiger Meilenstein im weltweiten KI-Wettlauf. Mit nur 20 Milliarden aktivierten Parametern erreicht Seed 1.5-VL eine Leistung, die mit Googles Gemini 2.5 Pro vergleichbar ist. Dabei setzt es Spitzenleistungen (SOTA) in vielen praktischen visuellen und interaktiven Aufgaben, und das alles mit deutlich geringeren Rechenkosten.
🚀 Was ist passiert?
Am 15. Mai 2025 hat ByteDance offiziell Seed 1.5-VL vorgestellt, die neueste Version seiner multimodalen KI-Modelle der Seed-Reihe. Seed 1.5-VL wurde mit über 3 Billionen Tokens hochwertiger multimodaler Daten (Text, Bilder und Videos) trainiert. Es vereint fortschrittliches visuelles Denken, Bildverständnis, Interaktion mit Benutzeroberflächen (GUI) und Videoanalyse in einer einzigen, optimierten Struktur.
Anders als aufgeblähte KI-Systeme nutzt Seed 1.5-VL eine Mixture of Experts (MoE) Architektur. Dabei wird nur ein Teil der insgesamt 20 Milliarden Parameter für jede Aufgabe aktiviert. Das verbessert die Recheneffizienz enorm und macht es ideal für echtzeitfähige, interaktive KI-Anwendungen auf Computern, Handys und in eingebetteten Systemen.
Trotz seiner vergleichsweise kompakten Größe erreichte Seed 1.5-VL Spitzenleistungen in 38 von 60 öffentlichen Tests, darunter:
- 14 von 19 Tests zum Videoverständnis
- 3 von 7 Aufgaben für GUI-Agenten (Benutzeroberflächen-Agenten)
In den Tests zeigte es herausragende Fähigkeiten bei komplexem Denken, Texterkennung (OCR), Bildinterpretation, Objekterkennung mit offenem Vokabular und der Analyse von Überwachungsvideos.
Seed 1.5-VL ist jetzt öffentlich über die Volcano Engine API und die Open-Source-Community auf Hugging Face und GitHub verfügbar.
📌 Wichtigste Punkte
- Multimodale Fähigkeiten: Verarbeitet Bilder, Videos, Text und GUI-Aufgaben mit menschenähnlichem Verständnis.
- Effizienz im Vordergrund: Nur 20 Milliarden aktive Parameter, bietet vergleichbare Ergebnisse wie Google Gemini 2.5 Pro zu niedrigeren Kosten.
- Spitzenleistungen (SOTA): Führend in 38 von 60 öffentlichen Tests, besonders bei Video- und GUI-Aufgaben.
- Praktische Anwendungen: Bereits getestet in der Texterkennung (OCR), Überwachungsanalyse, Prominentenerkennung und Interpretation metaphorischer Bilder.
- Freier Zugang: Live-API auf Volcano Engine, wissenschaftliche Arbeit auf arXiv und Code auf GitHub.
🔍 Tiefergehende Analyse
Architektur & Neuerungen
Seed 1.5-VL basiert auf drei Hauptmodulen:
- SeedViT Visual Encoder: Ein Encoder mit 532 Millionen Parametern, der detaillierte Merkmale aus Bildern und Video-Frames extrahiert.
- MLP Adapter: Verbindet den Visual Encoder mit dem Sprachmodell, indem er Bild-/Video-Merkmale in multimodale Tokens umwandelt.
- Großes Sprachmodell: Ein MoE-basiertes LLM mit 20 Milliarden Parametern, optimiert für effiziente Berechnungen.
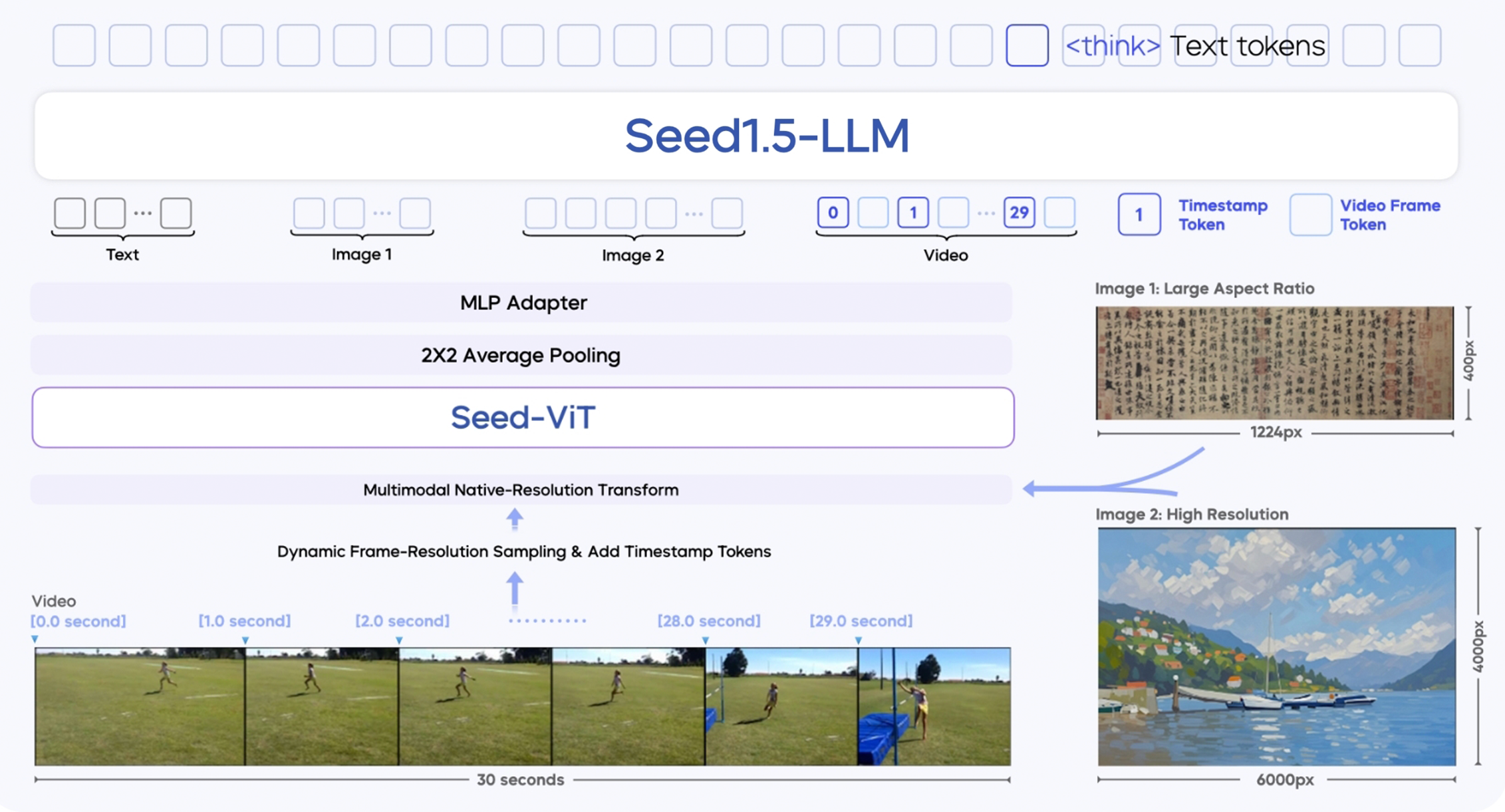
Es enthält mehrere technische Neuerungen:
- Unterstützung mehrerer Auflösungen bei der Eingabe: Sorgt für gleichbleibende Bildqualität und Genauigkeit.
- Dynamische Auswahl von Videobildern: Verbessert das Videoverständnis durch Auswahl von Frames basierend auf der Bewegungskomplexität.
- Besseres Zeitverständnis durch Zeitstempel: Verfolgt Objektabfolgen und Ursachen in Videos besser.
- Training mit über 3 Billionen multimodalen Tokens: Verbessert die Fähigkeit, sich an verschiedene Bereiche anzupassen.
- Verbesserungen nach dem Training: Beinhaltet Techniken wie Rejection Sampling und Online-Verstärkungslernen, um die Antwortqualität fein abzustimmen.
Stärken
Seed 1.5-VL glänzt bei:
- Visuellen Fragen und Antworten (VQA) sowie der Interpretation von Diagrammen
- Aufgaben zur Automatisierung von Benutzeroberflächen (GUI), einschließlich Spielen und App-Steuerung
- Interaktivem Denken in offenen visuellen Umgebungen
- Anwendungen in der Praxis, wie Prominentenerkennung, Überwachung und Verstehen von Metaphern
Es wird für seine Robustheit in der Praxis gelobt, die vielen wissenschaftlichen Modellen fehlt. Mehrere Tester bezeichneten es sogar als "ungewöhnliches Kraftpaket", das mit OpenAIs o4 und Googles Gemini mithalten kann.

Einschränkungen
Trotz seiner Stärken ist Seed 1.5-VL nicht fehlerfrei:
- Probleme bei sehr detailreichen visuellen Aufgaben: Schwierigkeiten beim Zählen von Objekten, die verdeckt sind, bei ähnlichen Farben oder unregelmäßigen Anordnungen.
- Schwierigkeiten bei komplexem räumlichem Denken: Aufgaben wie das Finden von Wegen in Labyrinthen oder das Lösen von Schiebepuzzles können zu unvollständigen Ergebnissen führen.
- Probleme beim Verfolgen von Abfolgen über die Zeit: Schwierigkeiten beim Verfolgen von Handlungsabfolgen über mehrere Frames hinweg.
ByteDance ist sich dieser Bereiche bewusst und wird diese wahrscheinlich in zukünftigen Versionen verbessern.
Wettbewerb
Seed 1.5-VL erscheint mitten in einem KI-Wettrüsten:
- Googles Gemini 2.5 Pro (6. Mai 2025) dominiert die multimodalen Bestenlisten (LMArena).
- OpenAIs o3 und o4-mini (17. April 2025) treiben die Nutzung multimodaler Tools und das Verstärkungslernen voran.
- Inländische Wettbewerber wie Tencent und Doubao haben ihre Bild- und Sprachfähigkeiten verbessert.
Investmentanalysten sind optimistisch: Agentenmodelle und multimodale Fähigkeiten gelten als wichtige Antriebe für KI-Anwendungen der nächsten Generation, insbesondere in den Bereichen Unternehmenssoftware, ERP-Systeme, Büroautomatisierung (OA), Coding-Assistenten und Büro-Tools.
💡 Wussten Sie schon?
- Seed 1.5-VL kann verdächtiges Verhalten in Überwachungsvideos erkennen – ein fortschrittlicher Anwendungsfall in der Praxis, den nur wenige Modelle effektiv bewältigen.
- Es ist eines der wenigen Modelle, das metaphorische Bilder interpretieren und abstrakte Beziehungen darin erklären kann.
- Weltweit sind nur 3 Modelle (Gemini Pro 2.5, OpenAI o4, Seed 1.5-VL) derzeit in der Lage, echtzeitfähige, interaktive Steuerung von Benutzeroberflächen (GUI) über verschiedene Datentypen hinweg zu ermöglichen.
- ByteDance schaffte es, mit der Leistung von Gemini Pro mithalten, indem es viel weniger Parameter nutzte. Das zeigt erstklassige Fähigkeiten bei der Modellkomprimierung und -optimierung.
- Seed 1.5-VL verwendet eine eigene Methode zur Erhaltung der Auflösung, die den bei herkömmlichen visuellen Encodern üblichen Qualitätsverlust vermeidet.
Abschließende Gedanken
Seed 1.5-VL ist ein wichtiger Meilenstein für ByteDance. Es zeigt, dass das Unternehmen ein weltweit führendes Unternehmen in der KI-Forschung ist, besonders bei multimodalen Basismodellen. Mit unübertroffener Recheneffizienz, Robustheit in der Praxis und Spitzenleistungen in wichtigen Tests hält es nicht nur mit Google und OpenAI Schritt – es konkurriert direkt.
Da die Nutzung von KI in allen Branchen zunimmt, werden Modelle wie Seed 1.5-VL an vorderster Front stehen. Sie werden intelligente Agenten formen, die Automatisierung vorantreiben und neu definieren, was Maschinen wahrnehmen, verstehen und tun können.
CTOL Editor Ken: Ich empfehle sehr, sich die Beispiele auf der offiziellen Seed 1.5-VL Seite von ByteDance anzusehen – sie sind wirklich beeindruckend.