
Wie man GPUs für Deep Learning und große Sprachmodelle auswählt
Bei der Auswahl von GPUs für Deep Learning-Arbeitslasten, insbesondere für das Training und den Betrieb großer Sprachmodelle (LLMs), müssen mehrere Faktoren berücksichtigt werden. Hier ist ein umfassender Leitfaden, der Ihnen hilft, die richtige Wahl zu treffen.
Tabelle: Neueste führende Open Source LLMs und ihre GPU-Anforderungen für den lokalen Einsatz
| Modell | Parameter | VRAM-Anforderung | Empfohlene GPU |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1.342GB | NVIDIA A100 80GB ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7GB | NVIDIA RTX 3060 12GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5GB | NVIDIA RTX 3080 10GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9GB | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7GB | NVIDIA RTX 4090 24GB ×2 |
| Llama 3 70B | 70B | ~140GB (geschätzt) | NVIDIA 3000 Serie, min. 32GB RAM |
| Llama 3.3 (kleinere Modelle) | Variiert | Mindestens 12GB VRAM | NVIDIA RTX 3000 Serie |
| Llama 3.3 (größere Modelle) | Variiert | Mindestens 24GB VRAM | NVIDIA RTX 3000 Serie |
| GPT-NeoX | 20B | 48GB+ VRAM gesamt | Zwei NVIDIA RTX 3090s (je 24GB) |
| BLOOM | 176B | 40GB+ VRAM für Training | NVIDIA A100 oder H100 |
Wichtige Überlegungen bei der Auswahl von GPUs
1. Speicheranforderungen
- VRAM-Kapazität: Vielleicht der wichtigste Faktor für LLMs. Größere Modelle benötigen mehr Speicher, um Parameter, Gradienten, Optimierer-Zustände und zwischengespeicherte Trainingsbeispiele zu speichern.
** Tabelle: Bedeutung von VRAM bei großen Sprachmodellen (LLMs).**
| Aspekt | Rolle von VRAM | Warum es entscheidend ist | Auswirkungen bei unzureichendem Speicher |
|---|---|---|---|
| Modell-Speicherung | Speichert Modell-Gewichte und Ebenen | Für effiziente Verarbeitung benötigt | Auslagerung auf langsameren Speicher; starker Leistungsabfall |
| Zwischenberechnung | Speichert Aktivierungen und Zwischendaten | Ermöglicht Echtzeit-Forward/Backward-Durchläufe | Begrenzt Parallelisierung und erhöht Latenz |
| Stapelverarbeitung | Unterstützt größere Stapelgrößen (Batch Sizes) | Verbessert Durchsatz und Geschwindigkeit | Kleinere Stapel; langsameres Training/Inferenz |
| Parallelisierungs-Unterstützung | Ermöglicht Modell-/Datenparallelisierung über GPUs hinweg | Notwendig für sehr große Modelle (z.B. GPT-4) | Begrenzt Skalierbarkeit über mehrere GPUs |
| Speicherbandbreite | Bietet schnellen Datenzugriff | Beschleunigt Tensor-Operationen wie Matrixmultiplikationen | Engpässe bei rechenintensiven Aufgaben |
- Berechnen Sie Ihren Bedarf: Sie können die Speicheranforderungen basierend auf Ihrer Modellgröße und Stapelgröße (Batch Size) schätzen.
- Speicherbandbreite: Höhere Bandbreite ermöglicht schnelleren Datentransfer zwischen GPU-Speicher und Verarbeitungskernen.
2. Rechenleistung
- CUDA-Kerne: Mehr Kerne bedeuten im Allgemeinen schnellere Parallelverarbeitung.
- Tensor-Kerne: Spezialisiert für Matrixoperationen, entscheidend für Deep Learning-Aufgaben.
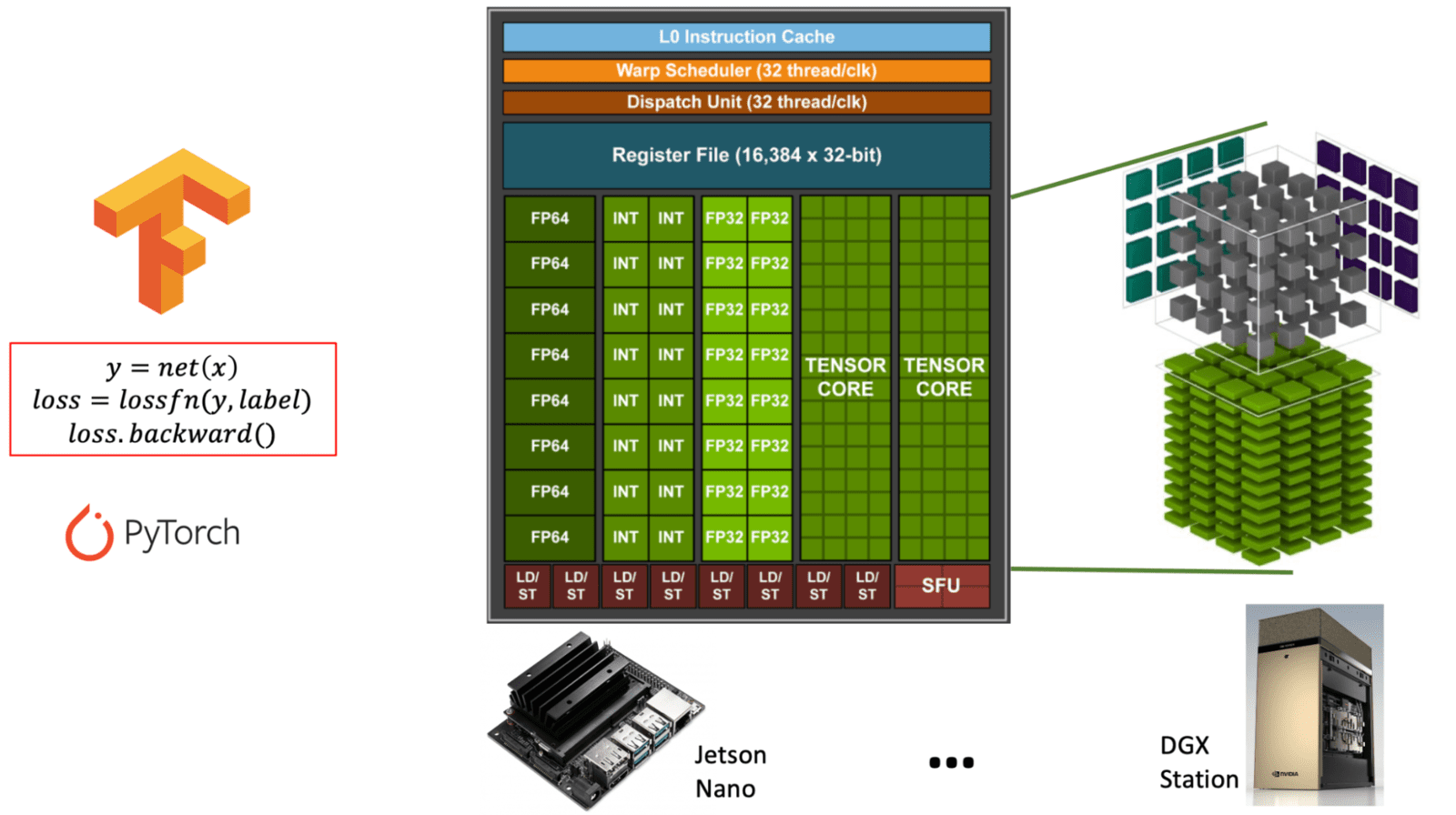
Diagramm, das den Unterschied zwischen Allzweck-CUDA-Kernen und spezialisierten Tensor-Kernen innerhalb einer NVIDIA-GPU-Architektur veranschaulicht. (learnopencv.com) - FP16/INT8-Unterstützung: Training mit gemischter Präzision (Mixed Precision) kann Berechnungen erheblich beschleunigen und gleichzeitig den Speicherverbrauch reduzieren.
** Tabelle: Vergleich von CUDA-Kernen vs. Tensor-Kernen in NVIDIA GPUs. Diese Tabelle erläutert Zweck, Funktion und Nutzung von CUDA-Kernen im Vergleich zu Tensor-Kernen, die beide für verschiedene Arten von GPU-Arbeitslasten, insbesondere in AI und Deep Learning, unerlässlich sind. **
| Merkmal | CUDA-Kerne | Tensor-Kerne |
|---|---|---|
| Zweck | Allzweck-Berechnung | Spezialisiert für Matrixoperationen (Tensor-Mathematik) |
| Hauptverwendung | Grafik, Physik und Standard-Parallelaufgaben | Deep Learning-Aufgaben (Training/Inferenz) |
| Operationen | FP32, FP64, INT, allgemeine Arithmetik | Matrixmultiplikations-Akkumulation (z.B. FP16, BF16, INT8) |
| Präzisionsunterstützung | FP32 (Single), FP64 (Double), INT | FP16, BF16, INT8, TensorFloat-32 (TF32), FP8 |
| Leistung | Moderate Leistung für Allzweckaufgaben | Extrem hohe Leistung für matrixintensive Aufgaben |
| Software-Schnittstelle | CUDA-Programmiermodell | Zugriff über Bibliotheken wie cuDNN, TensorRT oder Frameworks (z.B. PyTorch, TensorFlow) |
| Verfügbarkeit | In allen NVIDIA GPUs vorhanden | Nur in neueren Architekturen vorhanden (Volta und später) |
| AI-Optimierung | Begrenzt | Stark für AI-Arbeitslasten optimiert (bis zu 10x+ schneller) |
3. Inter-GPU-Kommunikation
- NVLink: Wenn Sie Multi-GPU-Setups verwenden, bietet NVLink eine erheblich schnellere GPU-zu-GPU-Kommunikation als PCIe.
NVLink ist eine von NVIDIA entwickelte Hochgeschwindigkeits-Verbindungstechnologie, die eine schnelle Kommunikation zwischen GPUs (und manchmal zwischen GPUs und CPUs) ermöglicht. Sie überwindet die Einschränkungen des traditionellen PCIe (Peripheral Component Interconnect Express), indem sie eine erheblich höhere Bandbreite und geringere Latenz bietet.
** Tabelle: Überblick über NVLink Bridge und seinen Zweck. Diese Tabelle umreißt Funktion, Vorteile und Schlüsselspezifikationen von NVLink im Kontext des GPU-basierten Rechnens, insbesondere für AI und Hochleistungs-Arbeitslasten. **
| Merkmal | NVLink |
|---|---|
| Entwickler | NVIDIA |
| Zweck | Ermöglicht schnelle, direkte Kommunikation zwischen mehreren GPUs |
| Bandbreite | Bis zu 600 GB/s gesamt in neueren Versionen (z.B. NVLink 4.0) |
| Vergleich zu PCIe | Viel schneller (PCIe 4.0: ~64 GB/s gesamt) |
| Latenz | Geringer als bei PCIe; verbessert die Effizienz bei Multi-GPU |
| Anwendungsfälle | Deep Learning (LLMs), wissenschaftliches Rechnen, Rendering |
| Funktionsweise | Verwendet eine NVLink Bridge (Hardware-Verbinder) zur Verbindung von GPUs |
| Unterstützte GPUs | High-End NVIDIA GPUs (z.B. A100, H100, RTX 3090 mit Einschränkungen) |
| Software | Funktioniert mit CUDA-fähigen Anwendungen und Frameworks |
| Skalierbarkeit | Ermöglicht es, dass sich mehrere GPUs eher wie eine einzige große GPU verhalten |
** Warum NVLink für LLMs und AI wichtig ist**
- Modellparallelisierung: Große Modelle (z.B. LLMs im GPT-Stil) sind zu groß für eine einzelne GPU. NVLink ermöglicht es GPUs, Speicher und Arbeitslast effizient zu teilen.
- Schnelleres Training und schnellere Inferenz: Reduziert Kommunikationsengpässe und steigert die Leistung in Multi-GPU-Systemen.
- Einheitlicher Speicherzugriff: Macht die Datenübertragung zwischen GPUs im Vergleich zu PCIe nahezu nahtlos und verbessert die Synchronisation und den Durchsatz.
- Training auf mehreren Karten: Für verteiltes Training über mehrere GPUs hinweg wird die Kommunikationsbandbreite entscheidend.
Zusammenfassungstabelle: Bedeutung der Inter-GPU-Kommunikation im verteilten Training
( Tabelle: Rolle der Inter-GPU-Kommunikation im verteilten Training. Diese Tabelle umreißt, wo schnelle GPU-zu-GPU-Kommunikation erforderlich ist und warum sie für das skalierbare, effiziente Training von Deep Learning-Modellen entscheidend ist. )
| Aufgabe im verteilten Training | Warum Inter-GPU-Kommunikation wichtig ist |
|---|---|
| Gradientensynchronisation | Stellt Konsistenz und Konvergenz in datenparallelen Setups sicher |
| Modell-Sharding | Ermöglicht nahtlosen Datenfluss in modellparallelen Architekturen |
| Parameter-Updates | Hält Modell-Gewichte über GPUs hinweg synchron |
| Skalierbarkeit | Ermöglicht effiziente Nutzung zusätzlicher GPUs oder Nodes |
| Leistung | Reduziert die Trainingszeit und maximiert die Hardware-Auslastung |
4. Stromverbrauch und Kühlung
- TDP (Thermal Design Power): Leistungsstärkere GPUs benötigen mehr Strom und erzeugen mehr Wärme.
- Kühllösungen: Stellen Sie sicher, dass Ihr Kühlsystem die Wärmeabgabe mehrerer Hochleistungs-GPUs bewältigen kann.
Vergleich beliebter GPU-Optionen
** Tabelle: Feature-Vergleich von NVIDIA GPUs für Deep Learning. Diese Tabelle vergleicht die wichtigsten Spezifikationen und Fähigkeiten der RTX 4090, RTX A6000 und RTX 6000 Ada und hebt ihre Stärken für Deep Learning-Arbeitslasten hervor. **
| Merkmal | RTX 4090 | RTX A6000 | RTX 6000 Ada |
|---|---|---|---|
| Architektur | Ada Lovelace | Ampere | Ada Lovelace |
| Erscheinungsjahr | 2022 | 2020 | 2022 |
| GPU-Speicher (VRAM) | 24 GB GDDR6X | 48 GB GDDR6 ECC | 48 GB GDDR6 ECC |
| FP32-Leistung | ~83 TFLOPS | ~38.7 TFLOPS | ~91.1 TFLOPS |
| Tensor-Leistung | ~330 TFLOPS (FP16, Sparsity aktiv) | ~312 TFLOPS (FP16, Sparsity) | ~1457 TFLOPS (FP8, Sparsity) |
| Tensor Core-Unterstützung | 4. Gen (mit FP8) | 3. Gen | 4. Gen (mit FP8-Unterstützung) |
| NVLink-Unterstützung | ❌ (Kein NVLink) | ✅ (2-Wege NVLink) | ✅ (2-Wege NVLink) |
| Stromverbrauch (TDP) | 450W | 300W | 300W |
| Formfaktor | Consumer (2 Steckplätze) | Workstation (2 Steckplätze) | Workstation (2 Steckplätze) |
| ECC Memory-Unterstützung | ❌ | ✅ | ✅ |
| Zielmarkt | Enthusiast / Prosumer | Professional / Data Science | Enterprise / AI Workstation |
| UVP (ca.) | ~1.450 EUR | ~4.200 EUR | ~6.100 EUR (variiert je nach Anbieter) |
RTX 4090
- Architektur: Ada Lovelace
- CUDA-Kerne: 16.384
- Speicher: 24GB GDDR6X
- Vorteile: Höchstes Preis-Leistungs-Verhältnis, hervorragend für Einzel-GPU-Arbeitslasten
- Einschränkungen: Keine NVLink-Unterstützung, weniger Speicher als professionelle Optionen
- Am besten für: Training mittelgroßer Modelle auf einer einzelnen GPU, Forscher mit begrenztem Budget
RTX A6000
- Architektur: Ampere
- CUDA-Kerne: 10.752
- Speicher: 48GB GDDR6
- Vorteile: Große Speicherkapazität, NVLink-Unterstützung, Stabilität auf professionellem Niveau
- Einschränkungen: Geringere Rohleistung als neuere Karten
- Am besten für: Speicherintensive Arbeitslasten, Multi-GPU-Setups, die NVLink benötigen
RTX 6000 Ada
- Architektur: Ada Lovelace
- CUDA-Kerne: 18.176
- Speicher: 48GB GDDR6
- Vorteile: Kombiniert neueste Architektur mit großem Speicher und NVLink
- Einschränkungen: Höherer Preis
- Am besten für: Kompromisslose Setups, bei denen das Budget keine Hauptrolle spielt
Spezielle Hardware-Optionen
SXM Formfaktor GPUs
** Tabelle: Vergleich von SXM- vs. PCIe-Formfaktoren für GPUs. Diese Tabelle umreißt die wichtigsten Unterschiede und Vorteile von SXM gegenüber Standard-PCIe für Deep Learning, HPC und Rechenzentrumsanwendungen. **
| Merkmal | SXM Formfaktor | PCIe Formfaktor |
|---|---|---|
| Verbindungstyp | Direkte Sockelschnittstelle (nicht über PCIe-Steckplatz) | Wird in PCIe-Steckplätze gesteckt |
| Stromversorgung | Bis zu 700W+ pro GPU | Typischerweise begrenzt auf 300–450W |
| Thermisches Design | Optimierte Kühlung über spezielle Kühlkörper, Optionen für Wasserkühlung | Luftgekühlt mit Standardlüftern |
| Bandbreite/Latenz | Unterstützt NVLink mit höherer Bandbreite und geringerer Latenz | Begrenzt auf die Geschwindigkeit des PCIe-Busses |
| GPU-Verbindung | NVLink-Mesh mit hoher Bandbreite zwischen mehreren GPUs | Geringere Bandbreite Peer-to-Peer über PCIe |